


How much of our water, electricity, tax breaks, and public land does it use?
Nice try, OpenAI sales reps.
But how much is the data you’re giving them worth? The other option is don’t give them your money or your data. The Qwen 3.6 MoE model with OpenCode is running pretty well on my RTX 4060 gaming laptop. According the Codscus YouTube channel, it even runs decently in as little as 6GB of VRAM.
Please do.
Use it all.
Bankrupt these shit companies and help burst the bubble
Sounds like a trap. Big cruises are said to have buffets, but yet, they’re still floating.
This is their strategy, they want people to use it, get hooked, replace parts of their day-to-day life with it, make it to difficult to “just go back”, then hit them with the actual bill.
They won’t go bankrupt unless their backers walk, and their backers are still quite confident in this strategy… because it’s working.
But no one is going to be able to afford a $14,000 subscription for slop.
Gov will bail them out and use our taxes to do it
I wonder what companies that have integrated AI into all their workflows and processes are planning to do when the times comes to pay real price for the tokens.
spoiler
Nothing. They aren’t thinking ahead.
That’s the next CEOs problem to solve while the current one is enjoying his golden parachute and sailing around the world. Right now, number is going up!
The companies don’t pay the price, they just pass it on to the consumer with a markup. Right now they just try stuff out to see what people really use AI for. Eventually the “AI features” will be cut back to the parts that really make them money, once they have to pay the real price.
All the investors know it’s a massive money sink right now. The goal isn’t for “everyone” to get to use AI.
It’s to get so many people used to using AI that businesses like law offices and hospitals and other corporations so ingrained and built around having AI, while leaving so many graduating college students useless without AI, that businesses will be reliant upon it, no matter what costs of it they will have to absorb.
In five years there won’t be a $200 plan. There will be a $15,000 plan per person and businesses will pay it because they won’t be able to do well without it.
I think there may also a horizontal scheme as monopolies take on a global scale. Those businesses that sell in bankruptcy due to high tech costs could be gobbled up by the biggest AI-native competition. It’s a leap but maybe in a decade your optometrist is replaced by an ai kiosk with a remote technician?
Maybe then he would give me the prescription I paid for…
See gym and carwash memberships
Is there a carwash membership???
Yeppers. Sign up for a monthly subscription with your cc, and no real way to cancel! “Unlimited”* car washes, so why would you ever cancel? You’re gonna want a clean car
The total I spent on AI is $0. How much AI can I get for that?
I would prefer none, but there’s AI being forced on us everywhere these days.
If you keep opening a new private tab and starting new conversations with chatgpt, your usage including uploads is free!
Also you can just switch to any other provider when you finish your free daily quota!!
Quite a bit if you actually wanted to use it. Opencode offers enough usage for free that you could create full apps from it lol, caveat being that their free plan usage is being used to train the models you use. But then everyone is probably doing it on their paid plans as well.
a little bit per maybe
This is just Gym Economics though, right? They work on the assumption that only a small number of their member will actually use the service heavily, but the overwhelming majority will turn up to use the treadmill a few times then never visit again.
Ok but it would take 70 users paying $200 to cover the cost of $14,000. So if one person maxes out their usage, there needs to be 69 users who do not use their account at all but are still paying. And that’s just the break even point, still no profit for the AI company.
I’m struggling to believe that many people would pay that much and then underuse the subscription. It seems far more likely to me that this pricing model isn’t sustainable.
Even worse, that calculation is based on that their API pricing is currently providing a positive margin. From what I have seen and heard at this point, API pricing is at best breaking even.
Nice try, I still ain’t gonna pay. OpenAI can go bankrupt without burning my money
If you’ve got a toy project that you want “AI” to give you a hand with, do it now.
Pretty soon all these companies are going to have to pay for all that investment in compute resources they’ve been busily soaking up over the last few years, and then they’re going to have to pay back their investors, and then they’re going to have to try and make a profit
This is the golden time for cheap commercial AI. Already the noose is starting to tighten, and it will never again be as cheap as it is now.
Another way to look at it would be “if you’ve got a toy project to practice coding without AI on, do it now” before that is the only option.
Yeah they’ve been pushing Claude code at work for us non coders jobs to come up with stuff that would help us. We’ve gotten a few surprisingly useful programs out of it, but our assumption is perfect them now before pricing goes through the roof. We are also only creating programs that do not require ongoing AI use. Just a bunch of relatively simple things that make our jobs easier.
I am still pushing my boss for some local hw as I think as a group we’ve spent a couple grand in the last month and that is the least of my reasons for wanting a local llm vs subscription.
This is the golden time for cheap commercial AI.
I suppose, but small open weight models with more advanced coding frameworks optimized for them are catching up fast and you can do it privately at home on a mostly affordable consumer graphics card.
If you have solar it’s basically free, minus the graphics card CapEx you may want for gaming anyway, as well as some setup time and a bit of patience.
Yes, it’s trending in that direction, and I’ve been experimenting with pretty small models on my PC as I don’t really have the hardware to go large. If you’ve got the coding chops to set it up, it’s definitely something to keep an eye on.
There’s actually scope for someone to set up / sell local compute hardware+software packages, similar to all those coin miners. Give the end user a way to update models, or push models out to them or something, it seems it would be a good middle ground between manually typing code like a peasant and total corporate AI apocalypse.
There’s actually scope for someone to set up / sell local compute hardware+software packages, similar to all those coin miners.
I think that’ll be a viable target in the future, and have little doubt some are jumping on it already. However, I also think it’s too much of a moving target currently, a near optimal setup changes almost entirely month to month.
I find myself targeting last months setup, as then there’s enough literature out there to get it set up in a day or two and most of the kinks have been worked out. Otherwise, I lose too much coding time to debugging the bleeding edge.
IMO, at the moment, if you’re not capable of setting it up yourself you likely don’t have the experience to use it reasonably safely nor an adequate understanding of its limitations. You’ll find yourself using more time fixing the blunders than you gain, and / or the project will spiral out of control in maintainability, security, readability, and so forth. You could get away with small projects written as ‘write only’ code ala Perl though, keep the prompts and tests, when it needs to change rebuild with the newest hotness. Inefficient and unsatisfying though.
What’s your setup, if I may ask? I’m using llama.cpp router with vscode kilo.ai and qwen3.6-35B-MoE-MTP as a model mostly. It’s surprisingly good as a coding assistant, but I think you have to know what you are doing and know your stuff(aka be an experienced developer) to make it useful. just letting it vibe leads to crap code
just letting it vibe leads to crap code
Yup, vibe is occasionally useful for proof of concept stuff, but disastrous for maintainability, security, readability, or large codebases. Without experience it’s still a foot gun for anything even slightly serious.
Best approaches for a learner are to consider it autocomplete that needs research. Look up what it’s suggesting, see if it’s hallucinating, with luck it’ll point you in a useful direction where you can learn a good solution, as it has no idea what that is. Also makes a pretty good rubber duck for hashing out architectural decisions, finding alternative approaches etc, though you’ll have to point it at a web search for that. Spin up an e.g. vane instance for this, as small models don’t have enough world knowledge. Use it to write (or preferably copy from its system prompt examples) boilerplate and unit tests, perhaps descriptive comments (doublecheck).
One thing to do is put everything you learn about coding style into your system prompt as they’re dogshit at consistent style without significant beatings around the head. Finding your own comfortable, consistent style is super useful for future readability. The joke about when I wrote this only God and I understood it, now only God does, will come clear in a month or two. Learn to work around it. Simple beats fancy unless you truly need the speed.
While I do use agent iterative approaches, probably best to approach that organically as you grow, monsters lurk there. If you must, containerize / vm / isolate the hell out of something like opencode to muck around with.
FWIW I still write most of my code by hand, it’s simpler and more consistent, but I’m keeping an eye on the development of LLMs, and I will let it write scut code (that I edit later). Code and Mathematics are super structured languages, pretty much ideal for large language models, so I can see them maybe, eventually getting good. More general thought, not so much without significant architectural upgrades.
While this advice is true for all models, when it comes to agentic tasks (add this small feature/write this test harness/find bugs/suggest improvements), open source models are still way behind, vibe code or not.
Claude Fable or even Opus in an editor like Zed have a 1 million token context window and will “think” through the goals of the application, test their changes, work through debugging processes the way a programmer would, stop to ask for clarification, check diagnostic tools and linters, prompt to run test code, etc.
Llama, Gemma and Qwen etc. Do lack a lot of the world knowledge to get the goals of the application, but they also just don’t have the debugging skills, won’t test their code, don’t always tool call correctly, get confused as the context increases and nobody has enough vram to run on large context sizes locally.
They can do autocomplete on small functions but aren’t really there for more complex tasks.
On top of that, the biggest problem is that the best open source models are trained and released by the same giant tech conglomerates that have an interest in not competing with their own products. Qwen is Alibaba, Llama is Meta, gpt-oss is OpenAI. Even the more “independent” ones, kimi (Moonshot) and GLM (z.ai) are mostly funded by Alibaba and Tencent. They’re released for research and marketing purposes and to please their corporate backers with inflated stock. Almost nobody has the resources to train new models from scratch. People make lots of merges and fine tunes but AI is not democratised the way that traditional programming tools have been.
Maybe some day there will be enough cheap compute for open source communities to pool together resources to build competing models but they’re not really there yet :(
Context management is a huge part of making smaller models viable (and likely a big part of making frontier models better). Tricks like structured context libraries for thinking improve things a lot, I like approaches that output things like an Obsidian vault that let you dig in and correct bad assumptions easily, even if it’s a bit slower. It’s a useful deliverable that can (mostly) be reused with updated models.
Things like ‘the debugging skills, won’t test their code, don’t always tool call correctly’ are tangibly improving model to model, framework to framework, and are problems that will be solved in time, but yes they need handholding ATM.
Things like
test their changes, work through debugging processes the way a programmer would, stop to ask for clarification, check diagnostic tools and linters, prompt to run test code
are mostly down to framework, not model (except for failing to tool call, which is improving), and falling at a respectable rate.
That said, sure, frontier models get more in one go, personally I’m fine with only a 3-4x force multiplier instead of 10 to keep it local, but YMMV. For a business with resources for a bigger server it’ll be more like 8 times. Remember that some businesses handle sensitive data and can’t (or damn well shouldn’t) use frontier models, so the market is there.
Maybe some day there will be enough cheap compute for open source communities to pool together resources to build competing models but they’re not really there yet :(
Not wrong, decentralized inference is mostly solved (with latency penalties), but without decentralized training true democratization will remain out of reach. Hopefully a breakthrough will ensue, but until then we are dependent on the kindness of corporations (or them rugpulling competitors).
This could also be a part of the RAMpocalypse thing, ‘if there’s not a moat I’ll fucking dig one, damn everyone else’ (and damn SamA). I doubt that’s sustainable long term, but it might get them through to IPO, more’s the pity.
Sounds like it’ll never be worth it.
In five years once this RAM nonsense is over you’ll be able to run a comparatively high quality local LLM for very little money. I can’t see how these companies will ever make their money back.
If manufacturers are willing to sell components to us in five years that is.
Of course if the colllapse happens before then the story might be different…
I’m slightly optimistic that manufacturers will return to the retail market eventually. Every AI company is racing to hyperscale right now but there will be a point where the infrastructure is built and at that point the growth will slow down quite a bit. In that scenario there will be ongoing demand for components to be replaced as they become obsolete but I can’t imagine the demand will be the same level it is right now as everyone rushes to build.
That’s assuming this all works the way they want it to. If the economics aren’t viable and the bubble bursts…
“Hyperscale” is utterly meaningless MBA jargon at this point. Equivalent of verbal slop from industry shills and CNBC/Bloomberg sell side simps.
Sorry if that’s true. I understood the word to mean aggressive growth at any cost to try and shut out competition before they can get established.
Their Datacenter buildout doesn’t work they want to. Most projects are very much delayed, and those that even started getting built are over budget. OpenAI and Anthropic will collapse in the next years, and this is coming from someone who absolutely sees the good things about the technology itself.
OpenAI and Anthropic will collapse in the next years
Stop, I can only handle so much good news!
There is no way, absolutely NO WAY to recuperate the amount of cash burnt on those two companies, and that is not even counting the amount of AI Startup whose cash is currently flowing towards to those two.
🤞
Sounds like price hikes to communicate costs are coming and resources are going to be redistributed to productive uses.
deleted by creator
The actual cost to OpenAI is likely much less. The number in the article is calculating the API cost that a fully maxed out subscription would incur theoretically. The API token cost, however, is far above the actual computational cost.
The actual price is hard to really know, but I think training should also factor in. The hype of LLMs is based on the fantastical idea of continunous improvement forever, so you need to keep training. Even ignoring the hype part, you still need to retrain simply to update the data inside the LLM.
I guess we’ll only know for sure after the crash/readjustment.
I disagree - the analysis takes as a basis a very, very generous margin of 75% on API prices. There is no way they have that much of a margin, this is wishful thinking.
And every single user who maxes out their 200$-subscription burns more cash than they take in from 70 subscriptions that lie dormant.
I was talking to one of our cloud architects at work yesterday. They did a test and just ran in “asdf” to a chat prompt, and were able to trace the costs. It was 12 cents.
I could totally see AI costs getting out of control very quickly. Doing something like a Copilot formula in an Excel spreadsheet is easily going to run up hundreds of dollars of costs eventually.
It’s a 200 dollar subscribtion. Are any actual users around that can provide info on how actively they are using it? I would feel that at 200 dollars they give you loads of headroom.
For Anthropic at least, your usage is broken up into five hour windows. During peak periods the usage is burnt in like 1/3 of the time compared to off-peak. You can do heaps, like build large sophisticated applications with 100% agentic workflows, if you spread your usage out over your five hour windows and especially if you use it mostly in the off peak.
On pro, your five hour usage is basically one solid feature developed or one big refactor/cleanup with opus 4.8 with some room left over for reviews, planning and a little mistake. 5x and 10x plans are more in the price range you mention, so multiply that as such. Or you’d get a combination of general purpose daily usage, and development usage.
There’s also a weekly cap but I haven’t hit it.
Fable, aka locked down mythos, when it was available on pro could complete my entire todo list for the day in half an hour at astounding quality while simplifying everything it touches, finding and fixing preexisting vulnerabilities in code review and finishing with 98% of the five hour quota used off-peak
I don’t think most hobbyists would use more than a quarter of a pro plan due to the five hour lockout mechanism
Bloomberg reports that the company has instituted a new rule that places a monthly $1,500 cap per employee and per agentic coding tool, including Anthropic’s Claude Code or Cursor. The usage is trackable via an internal dashboard that each employee has access to, although — in certain cases — the caps can be exceeded with permission, the company says.
The news is perhaps not too surprising, since, in April, the company’s CTO revealed that the ridesharing giant had blown through its entire annual AI budget in a matter of four months. That appears to have occurred after Uber encouraged staff to use AI “as much as possible” and even ranked their internal usage competitively on internal leader boards, The Information previously reported.
This isn’t that relevant to my question.
So far i pay 10 bucks for opencode
And i think thats about the highest i will pay
Preferably less
Opencode Go is a pretty good value for the amount of credits you get and the TUI and web/desktop client is pretty good.
I’m really happy switching to opencode after copilot got ridiculous with their pricing bullshit this month
Yeah it’s a steal right now. They lose around 50$ in raw token cost if you max out the use.
Very much not sustainable business model either just like copilot wasn’t.
those who subscribed should set up bots to use that full potential
let AI write that bot
Do you want a Butlerian Jihad? Because that’s how you get a Butlerian Jihad
Hopefully it doesn’t crash when the usage goes up a bit.
Here is the second part of the table btw, with an illusory 75% margin on API pricing:
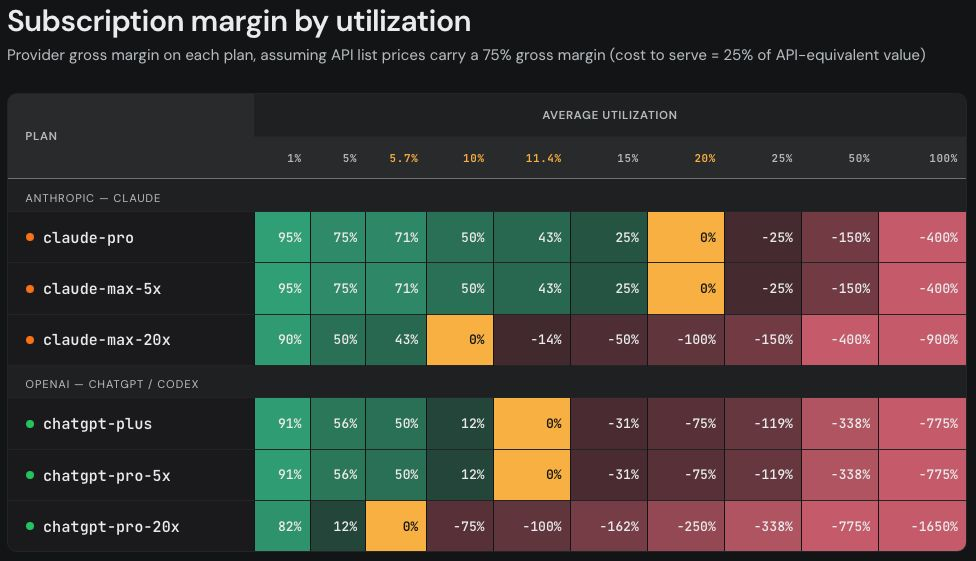
This will never be profitable if not specialized into very specific areas with very large payoffs. Even coding isn’t paying off enough.











