Coding with LLMs (Claude Code, OpenAI Codex) is often presented as the ‘killer app’ for Generative AI. But looking at data, it seems the one piece of the puzzle missing is actual cost. …
I’ve got an old 1060ti in my server. Ollama shares it with just a couple other containers. Electricity here is majority hydro with some natural gas, $0.08/kWh.
It’s a little slow, but I can comfortably run qwen3:14b. Of course that’s not all done on the GPU, a large part is offloaded to server ram (generally 32GB available so more than enough headroom)
My server and my gaming PC combined last month came out to $13.32
I remember my computer not being fast enough to even play an MP3 file. Two years later, my computer was capable of running 3D accelerated games, browsing the internet at broadband speeds and playing videos.
Sometimes technology advances fast. We could be entering such an era as there are major investments taking place and global competitors will rise to the occasion to market these to a broader audience.
I think it will be entirely possible for consumers to use a decent LLM on their computer in a few years time.
It’s not the 90s anymore. Unless there’s a compression algorithm putting billions of relationships into a manageable size, local AI is highly specific under 8G vram (text-to-speech as an example is under 1G) let alone the context required for keeping a conversation or writing code.
Improved hardware capabilities used to come very quickly (see Moore’s Law and Dennard Scaling). However that trend is basically over, so getting higher performance hardware takes a lot of effort to make hardware specialized for certain tasks. That’s why you see there inference accelerators like Groq, SambaNova, Cerebrus, etc. However this is hardware that still is gonna go into data centers. Something innovative has to happen on the AI side for commercial-grade models to be runnable on consumer hardware.

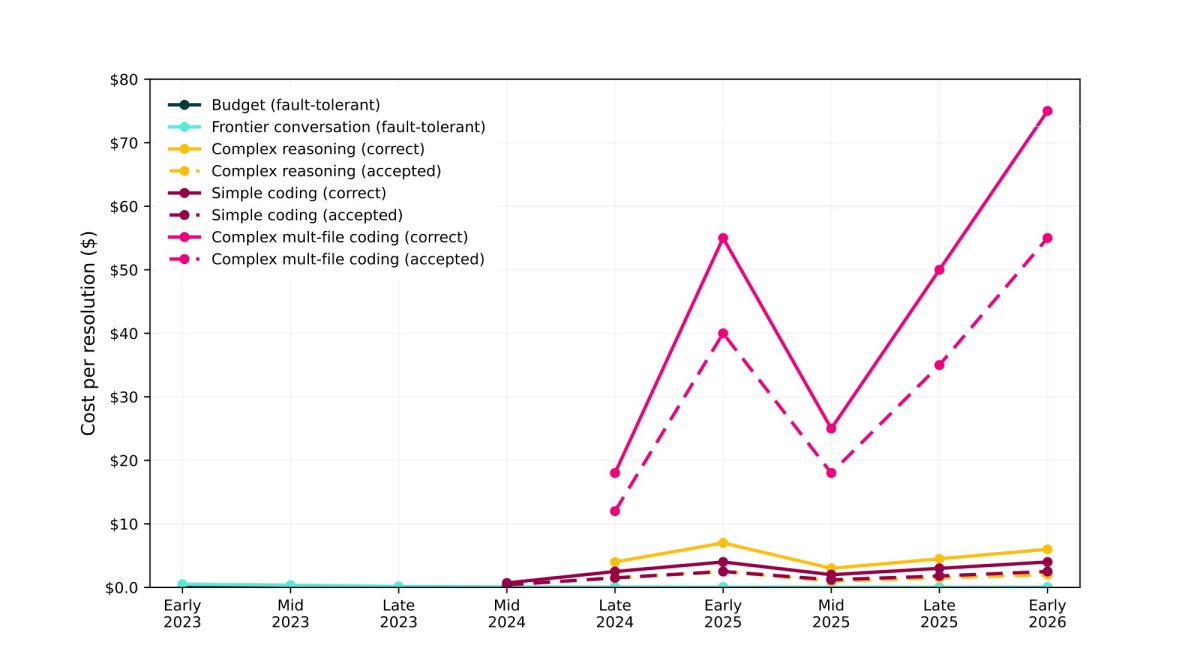
What’s the cost of the compute you have to run something locally?
Majority of people don’t have 32G of vram to run something remotely as capable
I’ve got an old 1060ti in my server. Ollama shares it with just a couple other containers. Electricity here is majority hydro with some natural gas, $0.08/kWh.
It’s a little slow, but I can comfortably run qwen3:14b. Of course that’s not all done on the GPU, a large part is offloaded to server ram (generally 32GB available so more than enough headroom)
My server and my gaming PC combined last month came out to $13.32
How does that compare to closed models that Anthropic offers, at the context and scale they offer.
I run Qwen3.6 27B locally and it’s usable with 16G vram but still not the same as a data centre of Blackwell clusters.
lfm2 works like greased lightning on the NPU built into the current macbook M5.
Describe greased lightning, because it’s much slower and needs to handle compression for context
We’re moving in that direction but an M5 is not what the majority of people are running at home
I dunno man, I’m not a slopjockey so I don’t know the minutiae of the addiction.
All of our devs appear to have M5s right now. All of those copilot+ laptops have NPUs too.
Your company has bought you the latest and greatest and likely supports commercial token usage too
You can’t compare LLMs at scale to running it locally; same experience and capabilities
“Latest and greatest” my fucking sides lmao
My company gave me some US shitware and I’ve got some local shitware instead.
If you can’t make that work and are dependent on the teat of the slopgenerators, that’s a skill issue on you, buddy.
I remember my computer not being fast enough to even play an MP3 file. Two years later, my computer was capable of running 3D accelerated games, browsing the internet at broadband speeds and playing videos.
Sometimes technology advances fast. We could be entering such an era as there are major investments taking place and global competitors will rise to the occasion to market these to a broader audience.
I think it will be entirely possible for consumers to use a decent LLM on their computer in a few years time.
It’s not the 90s anymore. Unless there’s a compression algorithm putting billions of relationships into a manageable size, local AI is highly specific under 8G vram (text-to-speech as an example is under 1G) let alone the context required for keeping a conversation or writing code.
To be clear, I wasn’t talking about a leap in LLM design. I was talking about a leap in hardware capabilities…
Improved hardware capabilities used to come very quickly (see Moore’s Law and Dennard Scaling). However that trend is basically over, so getting higher performance hardware takes a lot of effort to make hardware specialized for certain tasks. That’s why you see there inference accelerators like Groq, SambaNova, Cerebrus, etc. However this is hardware that still is gonna go into data centers. Something innovative has to happen on the AI side for commercial-grade models to be runnable on consumer hardware.
Which are increasingly out of reach for a normal person. Phones let alone PC hardware have increased exponentially in recent history