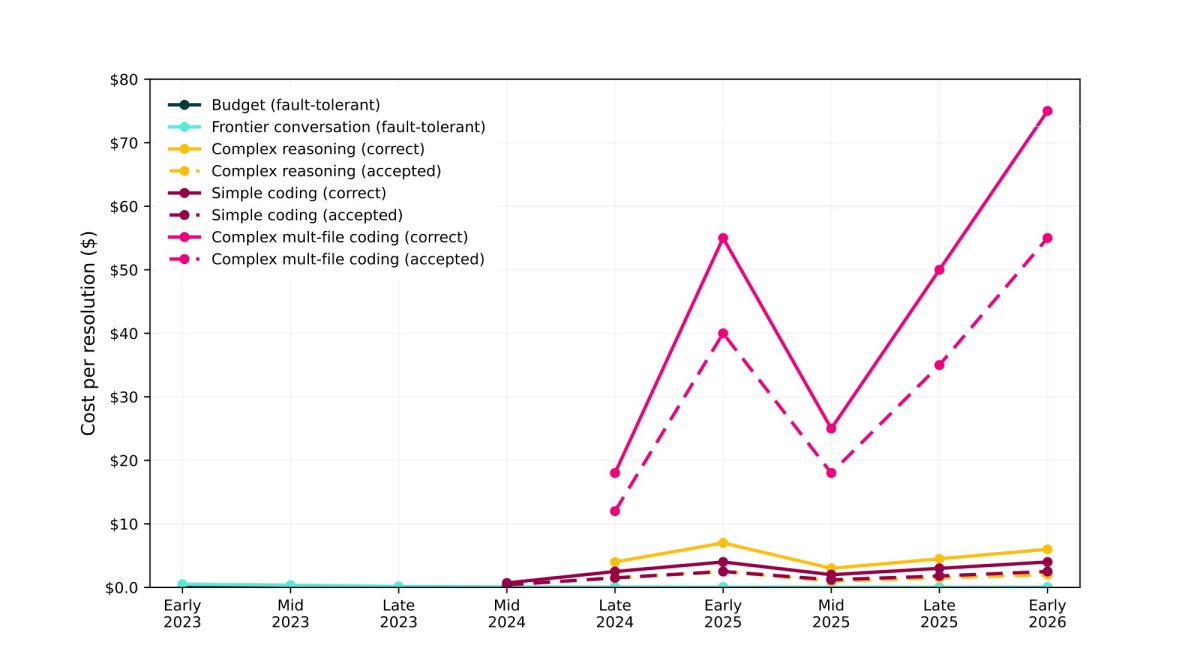
Coding with LLMs (Claude Code, OpenAI Codex) is often presented as the ‘killer app’ for Generative AI. But looking at data, it seems the one piece of the puzzle missing is actual cost. …
It’s not the 90s anymore. Unless there’s a compression algorithm putting billions of relationships into a manageable size, local AI is highly specific under 8G vram (text-to-speech as an example is under 1G) let alone the context required for keeping a conversation or writing code.
Improved hardware capabilities used to come very quickly (see Moore’s Law and Dennard Scaling). However that trend is basically over, so getting higher performance hardware takes a lot of effort to make hardware specialized for certain tasks. That’s why you see there inference accelerators like Groq, SambaNova, Cerebrus, etc. However this is hardware that still is gonna go into data centers. Something innovative has to happen on the AI side for commercial-grade models to be runnable on consumer hardware.

It’s not the 90s anymore. Unless there’s a compression algorithm putting billions of relationships into a manageable size, local AI is highly specific under 8G vram (text-to-speech as an example is under 1G) let alone the context required for keeping a conversation or writing code.
To be clear, I wasn’t talking about a leap in LLM design. I was talking about a leap in hardware capabilities…
Improved hardware capabilities used to come very quickly (see Moore’s Law and Dennard Scaling). However that trend is basically over, so getting higher performance hardware takes a lot of effort to make hardware specialized for certain tasks. That’s why you see there inference accelerators like Groq, SambaNova, Cerebrus, etc. However this is hardware that still is gonna go into data centers. Something innovative has to happen on the AI side for commercial-grade models to be runnable on consumer hardware.
Which are increasingly out of reach for a normal person. Phones let alone PC hardware have increased exponentially in recent history