

45·
2 days agoI mean…I tend to take potential lithium fires seriously, especially when they’re in my everyday carry. Companies don’t issue recalls and mass-replace units on a whim.

I’m surprisingly level-headed for being a walking knot of anxiety.
Ask me anything.
Special skills include: Knowing all the “na na na nah nah nah na” parts of the Three’s Company theme.
I also develop Tesseract UI for Lemmy/Sublinks
Avatar by @[email protected]
I mean…I tend to take potential lithium fires seriously, especially when they’re in my everyday carry. Companies don’t issue recalls and mass-replace units on a whim.
HAHAHA. 🤦♂️ I’ve called them “Ankler” for freaking years and am just today learning it’s “Anker”.
It’s “Downtown Abbey” all over again lol.
No, they’re on the form. Was just providing experience of what the process is like in case people expect it to be super painful.
Yep. I’ll note that in the post. Thanks.
Process was pretty easy. Basically you have to:
I dunno, and I’m not judging, but having had people close to me suffer from eating disorders, that arm upsets me lol.
Doesn’t matter what it is; it’s edible, and the owner of that arm desperately needs to eat it.
It’s rare when I agree with Marsha Blackburn on anything, but broken clocks and all that.

While [insert ad company name] products are a little more expensive, the quality and customer service are unmatched. It evens out when you use the [insert ad company name] reward card which gives 5% off each purchase.

AFAIK, yes. Though I haven’t tried it with WPA3.
While WEP is dead, you can still use it to capture the WPA/2 handshake and run it through something like John the Ripper to try to recover the passphrase.
Admittedly, I haven’t messed with it in years.
Either way, you still need a wireless adapter that’s capable of promiscuous mode as well as a driver for it that supports packet injection (not sure how rare that is nowadays).
When I was in college, I rented a house just outside my budget and found I couldn’t afford things like cable internet.
I had a wifi->ethernet bridge that was originally to connect my OG Xbox to a wifi network. I also had neighbors with Wifi using WEP encryption. An idea was born.
Was able to use aircrack-ng on my laptop to crack their WEP key in about 15 minutes. Plugged that key into my wifi->ethernet bridge, and then hooked that into my router. Bam, my whole house was online.
That worked for probably a year and a half.
I’ve always had uncannily good luck on Friday the 13ths. I think I’m gonna start making wishes. 🤔
I think I also recall some comments from somewhere from UK people saying Fahrenheit makes more sense for weather-related temperature.
But yeah, definitely human inconsistency lol.
Not a shit meme at all ! In fact, I want to convert that to ASCII art and have it as the MOTD when I sudo -i or console in as root.
Assuming it’s this (LAPQO71A) …
Guide: https://cdn.cs.1worldsync.com/a5/d0/a5d06ff2-92b9-4510-a5af-b71e1deb4083.pdf
Page 20

Looks to be on the left (in the image) below the fan and underneath where your hand is in the image.
Yep. Not sure when that became common, but my late 90s and early 2000s vehicles were like that. My late-model domestic car is all metric, though, so at least Ford standardized.
Hey, we use grams and kilos for…other things too.
It is funny how we’re schizophrenic about it, though. Things will go from grams to ounces and then to kilos…or, so I’ve heard.
Edit: American cars are also kind of schizo like that, or at least they used to be. The engine and everything attached to it was metric and everything else was SAE. Fun times.
and apparently custom thumbnails do not work good on lemmy either
Still??!
I know they worked in 0.19.7 and federated, but broke at least as of 0.19.9. I thought those were fixed in 0.19.11. Ugh.
I mean, it was only like 6 months ago lol
Though it feels like 60 years.






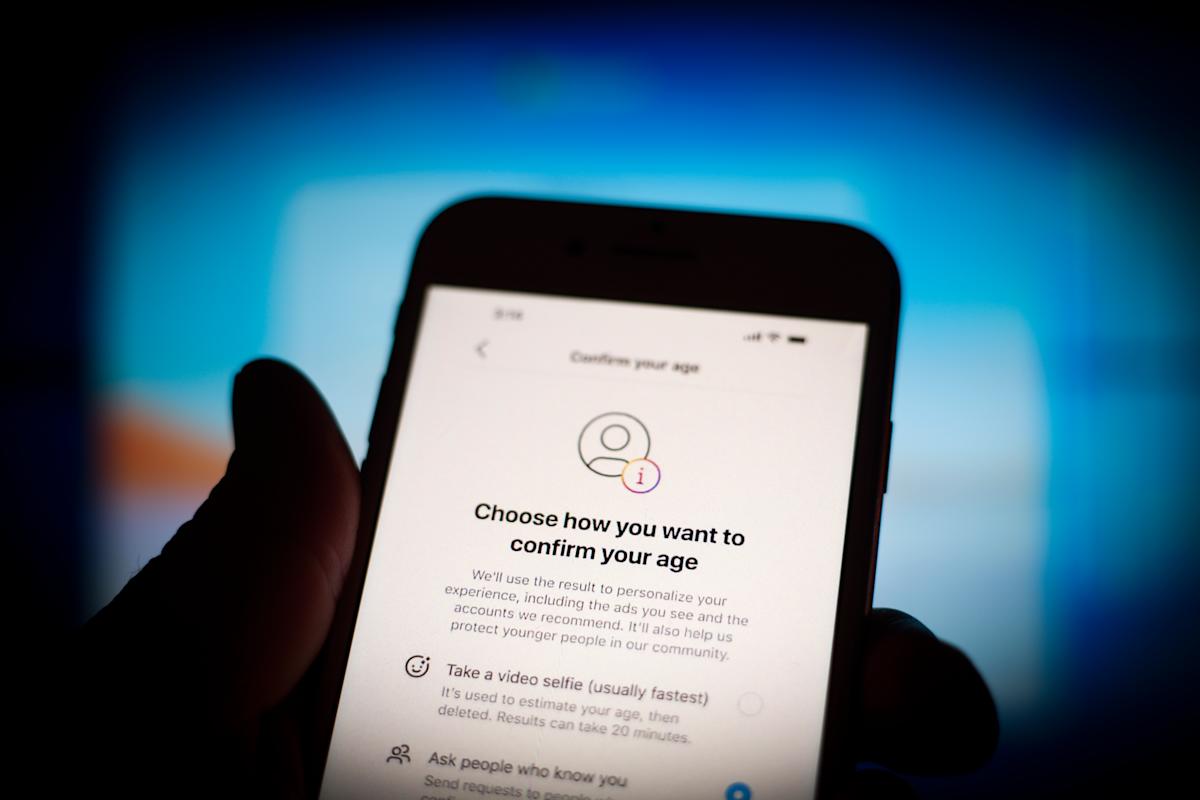


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Probably different batches. Recall info said it was due to an issue with a single supplier. Not even all of the listed models are affected, just certain serial numbers for each model.