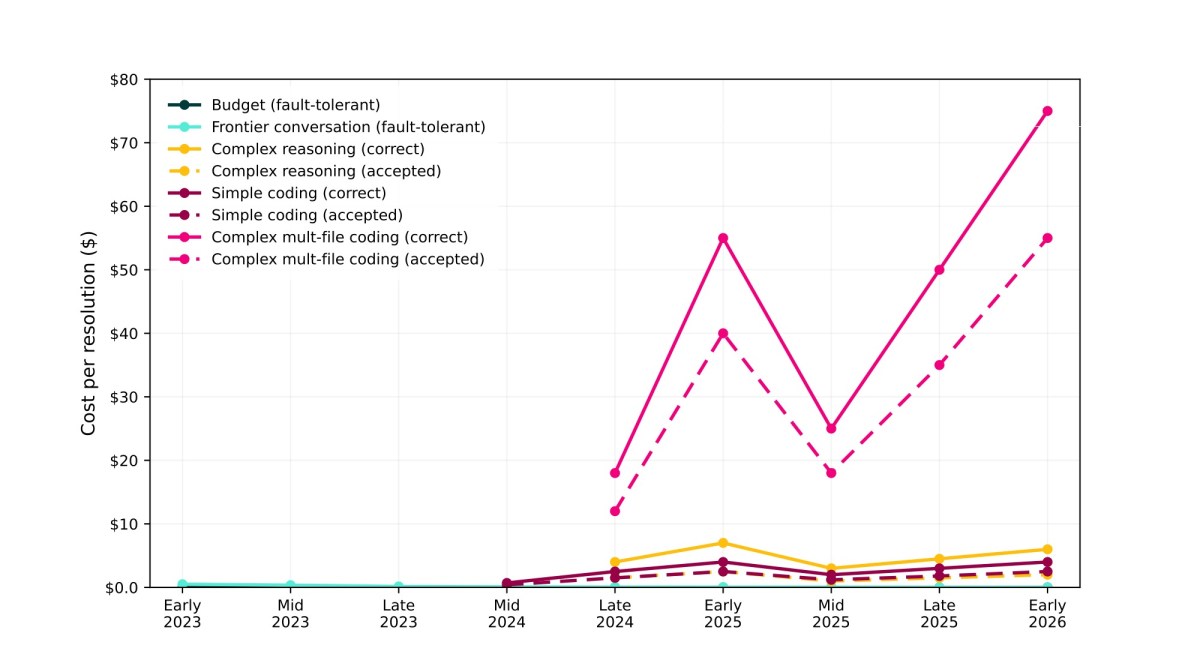
Coding with LLMs (Claude Code, OpenAI Codex) is often presented as the ‘killer app’ for Generative AI. But looking at data, it seems the one piece of the puzzle missing is actual cost. …
Both Uber and Spotify (and AWS too) had economics of scale going for them - the more users they have, the more the infrastructure could be leveraged. This does NOT work for LLMs. More users means using more compute, more advanced tasks (like coding) uses exponential amounts of compute. A single user running a complex task can make 8 Blackwell GPUs run full tilt, and you don’t even have any guarantee that the output will be useable.
There are a few narrow areas where LLMs might be successful, like scanning for security vulnerabilities or searching large amounts of documents. The massive amount of money invested will never be recouped with these usage scenarios.
Although, most people aren’t talking about Alphafold when they’re talking about AI. They’re usually specifically referring to the generative transformer models that are currently all the rage.
I doubt anyone would care too much about a linear regression model, or multi-layer peceptron , for example.
To clarify, my argument is that you don’t know what you’re talking about.
Erodos unit distance conjecture is a proposed solution to a Erodos unit distance problem. What the LLM model did was disproving Erodos unit distance conjecture, not solving it (you don’t solve a conjecture), nor solving the problem (that remains unsolved).
Again, you seem poisoned by following news media cycle without understanding what they talk about.
Multiple new vectors of attacks, automation of attack pipelines…

deleted by creator
Both Uber and Spotify (and AWS too) had economics of scale going for them - the more users they have, the more the infrastructure could be leveraged. This does NOT work for LLMs. More users means using more compute, more advanced tasks (like coding) uses exponential amounts of compute. A single user running a complex task can make 8 Blackwell GPUs run full tilt, and you don’t even have any guarantee that the output will be useable.
There are a few narrow areas where LLMs might be successful, like scanning for security vulnerabilities or searching large amounts of documents. The massive amount of money invested will never be recouped with these usage scenarios.
deleted by creator
Although, most people aren’t talking about Alphafold when they’re talking about AI. They’re usually specifically referring to the generative transformer models that are currently all the rage.
I doubt anyone would care too much about a linear regression model, or multi-layer peceptron , for example.
deleted by creator
Tell me you listen to media news cycle without understanding what that actually mean without telling me that.
That’s not exactly what happened, isn’t it.
Multiple new vectors of attacks, automation of attack pipelines…
deleted by creator
To clarify, my argument is that you don’t know what you’re talking about.
Erodos unit distance conjecture is a proposed solution to a Erodos unit distance problem. What the LLM model did was disproving Erodos unit distance conjecture, not solving it (you don’t solve a conjecture), nor solving the problem (that remains unsolved).
Again, you seem poisoned by following news media cycle without understanding what they talk about.
Like literally just put that into Google, it’s not some study that proves it, it’s the multiple ones, and every cybersecurity expert talking about it. But if you want a one source you want to argue about, then https://blog.checkpoint.com/research/global-cyber-attacks-rise-in-january-2026-amid-increasing-ransomware-activity-and-expanding-genai-risks/