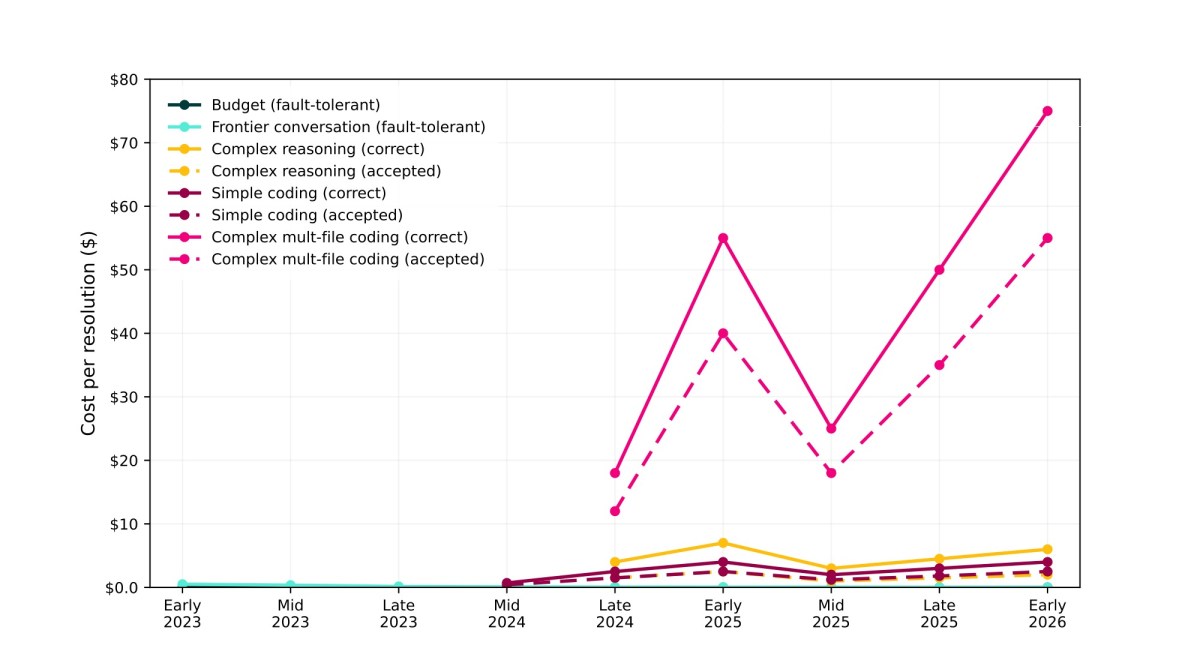
Coding with LLMs (Claude Code, OpenAI Codex) is often presented as the ‘killer app’ for Generative AI. But looking at data, it seems the one piece of the puzzle missing is actual cost. …
I think a lot of people just want to conclude that AI is going to “go away”, and latch on to beliefs that lead to this conclusion.
I think a lot of AI companies are likely to “go away.” That’s what happened when the dot com bubble popped, if there is indeed an AI bubble then we’ll see a similar massacre at the stock market. But the technology itself is sound, just like how the basic idea of e-commerce didn’t vanish with the dot-coms.
I’ve been doing a lot of fiddling with locally-run AI models and I’m thinking that the local open-weight models will be good enough to perform 90% of the tasks that most of us are currently depending on those big companies like Anthropic and OpenAI for. That’s going to let a lot of the air out of them when the applications catch up and start using those cheaper commodity-level models instead. For now it’s easier to just throw an OpenAI API key into your application and let it use the heavyweight models for everything, a powerful model can do simple tasks just as well as a simple model. Most tasks are simple but adding the ability to distinguish those tasks from the complicated ones is hard.
I like my local LLM too, but it’s one thing to utilize my existing VRam for a model that fits in there for fault tolerant tasks, and a whole other thing to utilize current frontier models which rack up an energy bill comparable to running a group of space heaters in a building which had to be designed for them, while not even having a guarantee that the output isn’t useless.
Right, which is why I said 90% and not 100%, and called out the challenge of deciding which tasks to send to which AIs. A lot of the interesting work I’m seeing in AI right now is in the agentic frameworks and harnesses that call the LLMs rather than just the LLMs themselves, these are the things that will break big complicated tasks down into more focused sub-tasks that cheaper LLMs can handle.
Given how some of the big providers like Gemini and Anthropic have been cranking up their API costs in recent weeks I expect we’ll see a lot more effort being put into rolling those sorts of features out.
It’s not even where to send it - you cannot predict how much any given task is going to cost you in tokens, which is the deciding factor in which model to use. The “cranking up” part has not even started yet, and we already have stories like Uber which blew through their complete AI budget for the year, what was it, 2 months ago? Uber is very pro-AI, so that budget was probably very generous. And to top it off, I haven’t seen or heard about anything new at Uber that would be even worth mentioning.
If you read the article, this project started from a clean slate and is 40k lines of code, so it’s peanuts in regards of complexity compared to what is out there in companies, and the author had to use the maximum power available to him to let Claude keep up. There still was no guarantee that the output was useable (and there can’t be such a guarantee, since hallucinations are a statistical fact, increasing in occurrence with smaller amounts of training Data available).
If you extrapolate this to an average IT stack, which has quirks and issues that are unique to it, you will never get anywhere you wouldn’t get by employing more engineers, who will get better over time and have fixed costs you can budget.
Remember, this is the “killer” application for LLMs. It looks a lot worse in EVERY other area except probably translation.
You can predict how much a task will take in tokens. The accuracy of the prediction may not be perfect, but if you can ballpark it that can tell you a lot about what models to make use of.
Also, not all tokens are the same. Different models require different amounts and kinds of computing power to run. Using a very large context costs more per token because you need a computer with a lot of memory to fit it all. If you need it fast that’s more expensive than if you an take your time. Does the task involve vision or audio? Does the context need to be saved for an ongoing chat? Does it need to wait for tool calls to return between rounds? There are a lot of variables that can be tweaked to vary the cost that an AI call will take, and a lot of those variables can be predicted without having to actually run the whole thing first.
The “cranking up” part has not even started yet, and we already have stories like Uber which blew through their complete AI budget for the year,
This is exactly what I’m talking about. Current LLM usage patterns tend to be pretty inefficient because people just thow tasks at the biggest and bestest models. Those models handle them, sure, because they’re the biggest and bestest. But most tasks don’t need that much.
I’ve used coding agents a fair bit along with the various other AI applications I’ve fiddled with, and often I ask them to do things that are dead simple. Create a function to sort some data and select whatever fits certain criteria. Add type checking to a file. Create a unit test for a function. Stuff like that could easily be done by a small local model, but the coding agent sends it off to Opus or whatever just like every other task. That can change.
There still was no guarantee that the output was useable (and there can’t be such a guarantee, since hallucinations are a statistical fact, increasing in occurrence with smaller amounts of training Data available).
I don’t think you’ve used modern coding AIs much.
Or, for that matter, worked with human coders.
Remember, this is the “killer” application for LLMs.
There is no one single “killer” application for LLMs. They’re about as general a computing platform as you can get.
I used to think like you, and I am still pro local LLMs - I use them as tutors for areas I don’t know much about, and since I use the output just as a guide and implement it on my own I quickly realize if something isn’t right.
We will see - when OpenAI and Anthropic rush towards IPO this year, which was made very likely because SpaceX has upped the tempo - what the real costs are. If this article and others I’ve read in the last year are correct, and the prices have to go up x10 to break even, then we are in for a wild ride. I’m only grateful that for now they don’t get lumped into the index funds.

I think a lot of people just want to conclude that AI is going to “go away”, and latch on to beliefs that lead to this conclusion.
I think a lot of AI companies are likely to “go away.” That’s what happened when the dot com bubble popped, if there is indeed an AI bubble then we’ll see a similar massacre at the stock market. But the technology itself is sound, just like how the basic idea of e-commerce didn’t vanish with the dot-coms.
I’ve been doing a lot of fiddling with locally-run AI models and I’m thinking that the local open-weight models will be good enough to perform 90% of the tasks that most of us are currently depending on those big companies like Anthropic and OpenAI for. That’s going to let a lot of the air out of them when the applications catch up and start using those cheaper commodity-level models instead. For now it’s easier to just throw an OpenAI API key into your application and let it use the heavyweight models for everything, a powerful model can do simple tasks just as well as a simple model. Most tasks are simple but adding the ability to distinguish those tasks from the complicated ones is hard.
I like my local LLM too, but it’s one thing to utilize my existing VRam for a model that fits in there for fault tolerant tasks, and a whole other thing to utilize current frontier models which rack up an energy bill comparable to running a group of space heaters in a building which had to be designed for them, while not even having a guarantee that the output isn’t useless.
Right, which is why I said 90% and not 100%, and called out the challenge of deciding which tasks to send to which AIs. A lot of the interesting work I’m seeing in AI right now is in the agentic frameworks and harnesses that call the LLMs rather than just the LLMs themselves, these are the things that will break big complicated tasks down into more focused sub-tasks that cheaper LLMs can handle.
Given how some of the big providers like Gemini and Anthropic have been cranking up their API costs in recent weeks I expect we’ll see a lot more effort being put into rolling those sorts of features out.
It’s not even where to send it - you cannot predict how much any given task is going to cost you in tokens, which is the deciding factor in which model to use. The “cranking up” part has not even started yet, and we already have stories like Uber which blew through their complete AI budget for the year, what was it, 2 months ago? Uber is very pro-AI, so that budget was probably very generous. And to top it off, I haven’t seen or heard about anything new at Uber that would be even worth mentioning.
If you read the article, this project started from a clean slate and is 40k lines of code, so it’s peanuts in regards of complexity compared to what is out there in companies, and the author had to use the maximum power available to him to let Claude keep up. There still was no guarantee that the output was useable (and there can’t be such a guarantee, since hallucinations are a statistical fact, increasing in occurrence with smaller amounts of training Data available).
If you extrapolate this to an average IT stack, which has quirks and issues that are unique to it, you will never get anywhere you wouldn’t get by employing more engineers, who will get better over time and have fixed costs you can budget.
Remember, this is the “killer” application for LLMs. It looks a lot worse in EVERY other area except probably translation.
You can predict how much a task will take in tokens. The accuracy of the prediction may not be perfect, but if you can ballpark it that can tell you a lot about what models to make use of.
Also, not all tokens are the same. Different models require different amounts and kinds of computing power to run. Using a very large context costs more per token because you need a computer with a lot of memory to fit it all. If you need it fast that’s more expensive than if you an take your time. Does the task involve vision or audio? Does the context need to be saved for an ongoing chat? Does it need to wait for tool calls to return between rounds? There are a lot of variables that can be tweaked to vary the cost that an AI call will take, and a lot of those variables can be predicted without having to actually run the whole thing first.
This is exactly what I’m talking about. Current LLM usage patterns tend to be pretty inefficient because people just thow tasks at the biggest and bestest models. Those models handle them, sure, because they’re the biggest and bestest. But most tasks don’t need that much.
I’ve used coding agents a fair bit along with the various other AI applications I’ve fiddled with, and often I ask them to do things that are dead simple. Create a function to sort some data and select whatever fits certain criteria. Add type checking to a file. Create a unit test for a function. Stuff like that could easily be done by a small local model, but the coding agent sends it off to Opus or whatever just like every other task. That can change.
I don’t think you’ve used modern coding AIs much.
Or, for that matter, worked with human coders.
There is no one single “killer” application for LLMs. They’re about as general a computing platform as you can get.
I used to think like you, and I am still pro local LLMs - I use them as tutors for areas I don’t know much about, and since I use the output just as a guide and implement it on my own I quickly realize if something isn’t right.
We will see - when OpenAI and Anthropic rush towards IPO this year, which was made very likely because SpaceX has upped the tempo - what the real costs are. If this article and others I’ve read in the last year are correct, and the prices have to go up x10 to break even, then we are in for a wild ride. I’m only grateful that for now they don’t get lumped into the index funds.